1.3. Slony-I Concepts
In order to set up a set of Slony-I replicas, it is necessary to understand the following major abstractions that it uses:
Cluster
Node
Replication Set
Origin, Providers and Subscribers
slon daemons
slonik configuration processor
It is also worth knowing the meanings of certain Russian words:
slon is Russian for "elephant"
slony is the plural of slon, and therefore refers to a group of elephants
slonik is Russian for "little elephant"
The use of these terms in Slony-I is a "tip of the hat" to Vadim Mikheev, who was responsible for the rserv prototype which inspired some of the algorithms used in Slony-I.
1.3.1. Cluster
In Slony-I terms, a "cluster" is a named set of PostgreSQL database instances; replication takes place between those databases.
The cluster name is specified in each and every Slonik script via the directive:
cluster name = something;
If the Cluster name is something, then Slony-I will create, in each database instance in the cluster, the namespace/schema _something.
1.3.2. Node
A Slony-I Node is a named PostgreSQL database that will be participating in replication.
It is defined, near the beginning of each Slonik script, using the directive:
NODE 1 ADMIN CONNINFO = 'dbname=testdb host=server1 user=slony';
The SLONIK ADMIN CONNINFO information indicates database
connection information that will ultimately be passed to the
PQconnectdb() libpq function.
Thus, a Slony-I cluster consists of:
A cluster name
A set of Slony-I nodes, each of which has a namespace based on that cluster name
1.3.3. Replication Set
A replication set is defined as a set of tables and sequences that are to be replicated between nodes in a Slony-I cluster.
You may have several sets, and the "flow" of replication does not need to be identical between those sets.
1.3.4. Origin, Providers and Subscribers
Each replication set has some origin node, which is the only place where user applications are permitted to modify data in the tables that are being replicated. This might also be termed the "master provider"; it is the main place from which data is provided.
Other nodes in the cluster subscribe to the replication set, indicating that they want to receive the data.
The origin node will never be considered a "subscriber." (Ignoring the case where the cluster is reshaped, and the origin is expressly shifted to another node.) But Slony-I supports the notion of cascaded subscriptions, that is, a node that is subscribed to some set may also behave as a "provider" to other nodes in the cluster for that replication set.
1.3.5. slon Daemon
For each node in the cluster, there will be a slon process to manage replication activity for that node.
slon is a program implemented in C that processes replication events. There are two main sorts of events:
Configuration events
These normally occur when a slonik script is run, and submit updates to the configuration of the cluster.
SYNC events
Updates to the tables that are replicated are grouped together into SYNCs; these groups of transactions are applied together to the subscriber nodes.
1.3.6. slonik Configuration Processor
The slonik command processor processes scripts in a "little language" that are used to submit events to update the configuration of a Slony-I cluster. This includes such things as adding and removing nodes, modifying communications paths, adding or removing subscriptions.
1.3.7. Slony-I Path Communications
Slony-I uses PostgreSQL DSNs in three contexts to establish access to databases:
SLONIK ADMIN CONNINFO - controlling how a slonik script accesses the various nodes.
These connections are the ones that go from your "administrative workstation" to all of the nodes in a Slony-I cluster.
It is vital that you have connections from the central location where you run slonik to each and every node in the network. These connections are only used briefly, to submit the few SQL requests required to control the administration of the cluster.
Since these communications paths are only used briefly, it may be quite reasonable to "hack together" temporary connections using SSH tunnelling.
The slon DSN parameter.
The DSN parameter passed to each slon indicates what network path should be used to get from the slon process to the database that it manages.
SLONIK STORE PATH - controlling how slon daemons communicate with remote nodes. These paths are stored in sl_path.
You forcibly need to have a path between each subscriber node and its provider; other paths are optional, and will not be used unless a listen path in sl_listen. is needed that uses that particular path.
The distinctions and possible complexities of paths are not normally an issue for people with simple networks where all the hosts can see one another via a comparatively "global" set of network addresses. In contrast, it matters rather a lot for those with complex firewall configurations, nodes at multiple locations, and the issue where nodes may not be able to all talk to one another via a uniform set of network addresses.
Consider the attached diagram, which describes a set of six
nodes
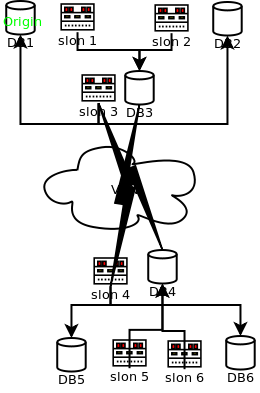
DB1 and DB2 are databases residing in a secure "database layer," firewalled against outside access except from specifically controlled locations.
Let's suppose that DB1 is the origin node for the replication system.
DB3 resides in a "DMZ" at the same site; it is intended to be used as a Slony-I "provider" for remote locations.
DB4 is a counterpart to DB3 in a "DMZ" at a secondary/failover site. Its job, in the present configuration, is to "feed" servers in the secure database layers at the secondary site.
DB5 and DB6 are counterparts to DB1 and DB2, but are, at present, configured as subscribers.
Supposing disaster were to strike at the "primary" site, the secondary site would be well-equipped to take over servicing the applications that use this data.
The symmetry of the configuration means that if you had two transactional applications needing protection from failure, it would be straightforward to have additional replication sets so that each site is normally "primary" for one application, and where destruction of one site could be addressed by consolidating services at the remaining site.
1.3.8. SSH tunnelling
If a direct connection to PostgreSQL can not be established because of a firewall then you can establish an ssh tunnel that Slony-I can operate over.
SSH tunnels can be configured by passing the w to SSH. This enables forwarding PostgreSQL traffic where a local port is forwarded across a connection, encrypted and compressed, using SSH
See the ssh documentation for details on how to configure and use SSH tunnels.